Update 2015-08-18: Boy do I feel silly! It turns out there’s a much simpler and much more robust way of doing what I’ve done with the scripts below. It turns out that, using any revision control system (eg. cvs, git, svn) that stores revisions as deltas (and most if not all do), all you need…
Tag: git
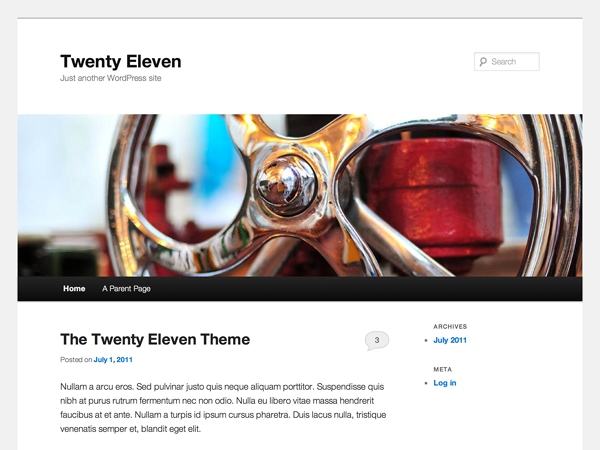
How to fix WordPress Twenty Eleven Featured Image
I like the Twenty Eleven theme and I still haven’t upgraded it. Luckily, some people are keeping it up to date and compatible with the latest WordPress in 2015! But there was one bug that bothered me for a long time and that was featured images were broken. These are the big header images at…
Request for a Versioning File System on Linux
The people who make file systems are developers. As a developer myself the value of a versioning file system is so keenly clear I’m so surprised it’s not, at the very least, a standard option on every single file system ever created. So this is a request to all the file system developers out there: Please, what can we do to get a versioning file system?
git – a love/hate relationship (with maybe a little more hate)
As per my previous post on git, we’ve been investigating and running trial repositories using git. So far, though, git has been frustrating me.
git – the fast version control system
At work, we’ve been investigating revision control systems to replace our current system, CVS. Primarily, we’re investigating git (wikipedia article) as it has basically become the de facto distributed version control system.